Asyncio
Asyncio is a co-operative multitasking library available in Python since version 3.6. Celery is fantastic for running concurrent tasks out of process, but there are certain times you would need to run multiple tasks in a single thread inside a single process.
If you are not familiar with async/await concepts (say from JavaScript or C#) then it involves a bit of steep learning curve. However, it is well worth your time as it can speed up your code tremendously (unless it is completely CPU-bound). Moreover, it helps in understanding other libraries built on top of them like Django Channels.
This post is an attempt to explain the concepts in a simplified manner rather than try to be comprehensive. I want you to start using asynchronous programming and enjoy it. You can learn the nitty gritties later.
All asyncio programs are driven by an event loop, which is pretty much an indefinite loop that calls all registered coroutines in some order until they all terminate. Each coroutine operates cooperatively by yielding control to fellow coroutines at well-defined places. This is called awaiting.
A coroutine is like a special function which can suspend and resume execution. They work like lightweight threads. Native coroutines use the async and await keywords, as follows:
import asyncio
async def sleeper_coroutine():
await asyncio.sleep(5)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(sleeper_coroutine())
This is a minimal example of an event loop running one coroutine named sleeper_coroutine. When invoked this coroutine runs until the await statement and yields control back to the event loop. This is usually where an Input/Output activity occurs.
The control comes back to the coroutine at the same line when the activity being awaited is completed (after five seconds). Then then coroutine returns or is considered completed.
Explain async and await
[TLDR; Watch my screencast to understand this section with a lot more code examples.]
Initially, I was confused by the presence of the new keywords in Python: async and await. Asynchronous code seemed to be littered with these keywords yet it was not clear what they did or when to use them.
Let’s first look at the async keyword. Commonly used before a function definition as async def, it indicates that you are defining a (native) coroutine.
You should know two things about coroutines:
- Don’t perform slow or blocking operations synchronously inside coroutines.
- Don’t call a coroutine directly like a regular function call. Either schedule it in an event loop or await it from another coroutine.
Unlike a normal function call, if you invoke a coroutine its body will not get executed right away. Instead it will be suspended and returns a coroutine object. Invoking the send method of this coroutine will start the execution of the coroutine body.
>>> async def hi():
... print("HOWDY!")
...
>>> o = hi()
>>> o
<coroutine object hi at 0x000001DAE26E2F68>
>>> o.send(None)
HOWDY!
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
However, when the coroutine returns it will end in a StopIteration exception. Hence it is better to use the asyncio provided event loop to run a coroutine. The loop will handle exceptions in addition to all other machinery for running coroutines concurrently.
>>> import asyncio
>>> loop = asyncio.get_event_loop()
>>> o = hi()
>>> loop.run_until_complete(o)
HOWDY!
Next we have the await keyword which must be only used inside a coroutine. If you call another coroutine, chances are that it might get blocked at some point, say while waiting for I/O.
>>> async def sleepy():
... await asyncio.sleep(3)
...
>>> o = sleepy()
>>> loop.run_until_complete(o)
# After three seconds
>>>
The sleep coroutine from asyncio module is different from its synchronous counterpart time.sleep. It is non-blocking. This means that other coroutines can be executed while this coroutine is awaiting the sleep to be completed.
When a coroutine uses the await keyword to call another coroutines, it acts like a bookmark. When a blocking operation happens, it suspends the coroutine (and all the coroutines who are await-ing it) and returns control back to the event loop. Later, when the event loop is notified of the completion of the blocking operation, then the execution is resumed from the await expression paused and continues onward.
Asyncio vs Threads
If you have worked on multi-threaded code, then you might wonder – Why not just use threads? There are several reasons why threads are not popular in Python.
Firstly, threads need to be synchronized while accessing shared resources or we will have race conditions. There are several types of synchronization primitives like locks but essentially, they involve waiting which degrades performance and could cause deadlocks or starvation.
A thread may be interrupted any time. Coroutines have well-defined places where execution is handed over i.e. co-operative multitasking. As a result, you may make changes to a shared state as long as you leave it in a known state. For instance you can retrieve a field from a database, perform calculations and overwrite the field without worrying that another coroutine might have interrupted you in between. All this is possible without locks.
Secondly, coroutines are lightweight. Each coroutine needs an order of magnitude less memory than a thread. If you can run a maximum of hundreds of threads, then you might be able to run tens of thousands of coroutines given the same memory. Thread switching also takes some time (few milliseconds). This means you might be able to run more tasks or serve more concurrent users (just like how Node.js works on a single thread without blocking).
The downsides of coroutines is that you cannot mix blocking and non-blocking code. So once you enter the event loop, rest of the code driven by it must be written in asynchronous style, even the standard or third-party libraries you use. This might make using some older libraries with synchronous code somewhat difficult.
If you really want to call asynchronous code from synchronous or vice versa, then do read this excellent overview of various cases and adaptors you can use by Andrew Godwin.
The Classic Web-scraper Example
Let’s look at an example of how we can rewrite synchronous code into asynchronous. We will look at a webscraper which downloads pages from a couple of URLs and measures its size. This is a common example because it is very I/O bound which shows a significant speedup when handled concurrently.
Synchronous web scraping
The synchronous scraper uses Python 3 standard libraries like urllib. It downloads the home page of three popular sites and the fourth is a large file to simulate a slow connection. It prints the respective page sizes and the total running time.
Here is the code for the synchronous scraper:
# sync.py
"""Synchronously download a list of webpages and time it"""
from urllib.request import Request, urlopen
from time import time
sites = [
"https://news.ycombinator.com/",
"https://www.yahoo.com/",
"https://github.com/",
]
def find_size(url):
req = Request(url)
with urlopen(req) as response:
page = response.read()
return len(page)
def main():
for site in sites:
size = find_size(site)
print("Read {:8d} chars from {}".format(size, site))
if __name__ == '__main__':
start_time = time()
main()
print("Ran in {:6.3f} secs".format(time() - start_time))
On a test laptop, this code took 5.4 seconds to run. It is the cumulative loading time of each site. Let’s see how asynchronous code runs.
Asynchronous web scraping
This asyncio code requires installation of a few Python asynchronous network libraries such as aiohttp and aiodns. They are mentioned in the docstring.
Here is the code for the asynchronous scraper – it is structured to be as close as possible to the synchronous version so it is easier to compare:
# async.py
"""
Asynchronously download a list of webpages and time it
Dependencies: Make sure you install aiohttp using: pip install aiohttp aiodns
"""
import asyncio
import aiohttp
from time import time
# Configuring logging to show timestamps
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='[%H:%M:%S]')
log = logging.getLogger()
log.setLevel(logging.INFO)
sites = [
"https://news.ycombinator.com/",
"https://www.yahoo.com/",
"https://github.com/",
]
async def find_size(session, url):
log.info("START {}".format(url))
async with session.get(url) as response:
log.info("RESPONSE {}".format(url))
page = await response.read()
log.info("PAGE {}".format(url))
return url, len(page)
async def main():
tasks = []
async with aiohttp.ClientSession() as session:
for site in sites:
tasks.append(find_size(session, site))
results = await asyncio.gather(*tasks)
for site, size in results:
print("Read {:8d} chars from {}".format(size, site))
if __name__ == '__main__':
start_time = time()
loop = asyncio.get_event_loop()
loop.set_debug(True)
loop.run_until_complete(main())
print("Ran in {:6.3f} secs".format(time() - start_time))
The main function is a coroutine which triggers the creation of a separate coroutine for each website. Then it awaits until all these triggered coroutines are completed. As a best practice, the web session object is passed to avoid re-creating new sessions for each page.
The total running time of this program on the same test laptop is 1.5 s. This is a speedup of 3.6x on the same single core. This surprising result can be better understood if we can visualize how the time was spent, as shown below:
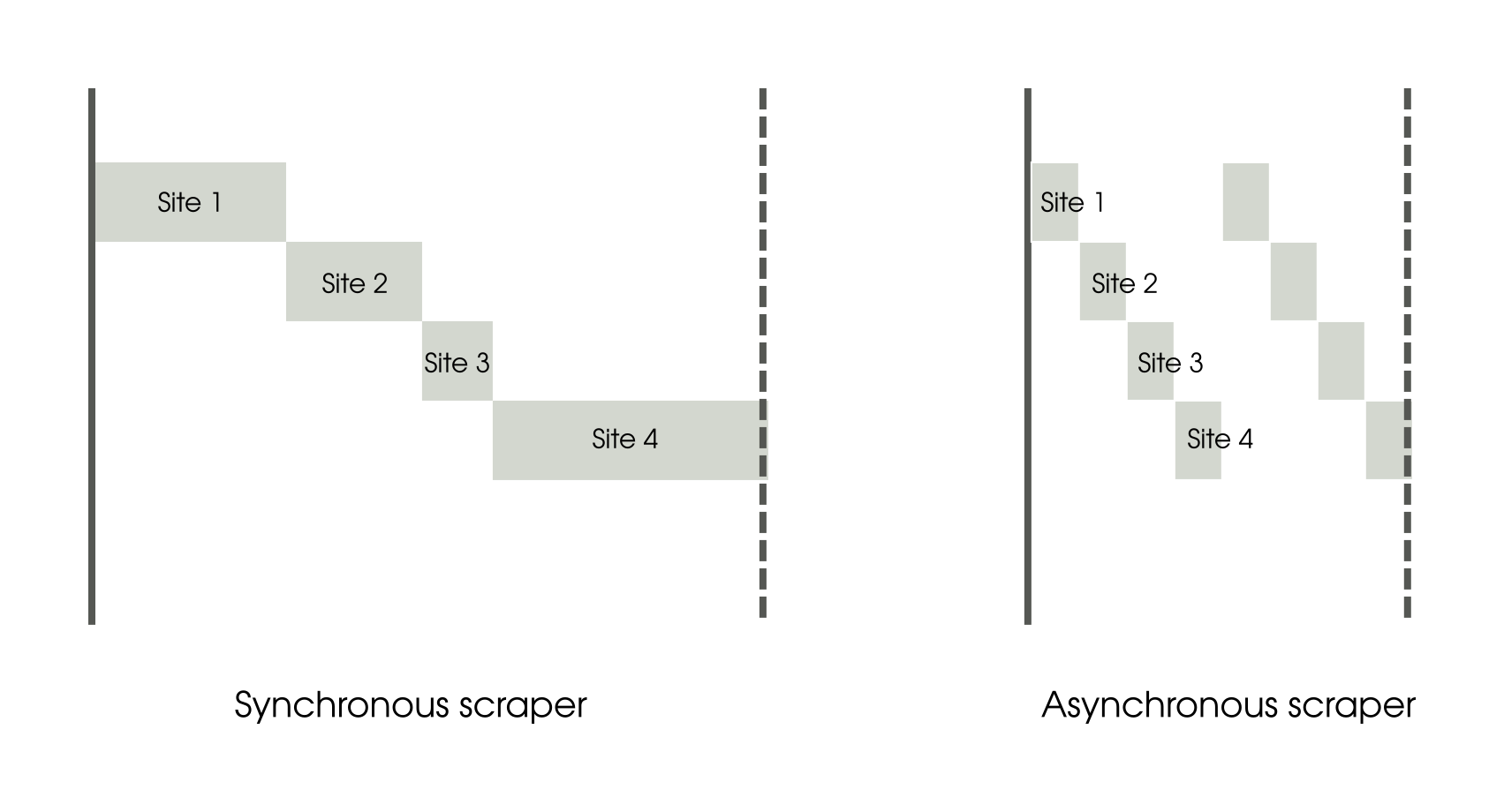
A simplistic representation comparing tasks in the synchronous and asynchronous scrapers
The synchronous scraper is easy to understand. Scraping activity needs very little CPU time and the majority of the time is spent waiting for the data to arrive from the network. Each task is waiting for the previous task to complete. As a result the tasks cascade sequentially like a waterfall.
On the other hand the asynchronous scraper starts the first task and as soon as it starts waiting for I/O, it switches to the next task. The CPU is hardly idle as the execution goes back to the event loop as soon as the waiting starts. Eventually the I/O completes in the same amount of time but due to the multiplexing of activity, the overall time taken is drastically reduced.
In fact, the asynchronous code can be speeded up further. The standard asyncio event loop is written in pure Python and provided as a reference implementation. You can consider faster implementations like uvloop for further speedup (my running time came down to 1.3 secs).
Concurrency is not Parallelism
Concurrency is the ability to perform other tasks while you are waiting on the current task. Imagine you are cooking a lot of dishes for some guests. While waiting for something to cook, you are free to do other things like peeling onions or cutting vegetables. Even when one person cooks, typically there will be several things happening concurrently.
Parallelism is when two or more execution engines are performing a task. Continuing on our analogy, this is when two or more cooks work on the same dish to (hopefully) save time.
It is very easy to confuse concurrency and parallelism because they can happen at the same time. You could be concurrently running tasks without parallelism or vice versa. But they refer to two different things. Concurrency is a way of structuring your programs while Parallelism refers to how it is executed.
Due to the Global Interpreter Lock, we cannot run more than one thread of the Python interpreter (to be specific, the standard CPython interpreter) at a time even in multicore systems. This limits the amount of parallelism which we can achieve with a single instance of the Python process.
Optimal usage of your computing resources require both concurrency and parallelism. Concurrency will help you avoid idling the processor core while waiting for say I/O events. While parallelism will help distribute work among all the available cores.
In both cases, you are not executing synchronously i.e. waiting for a task to finish before moving on to another task. Asynchronous systems might seem to be the most optimal. However, they are harder to build and reason about.
Why another Asynchronous Framework?
Asyncio is by no means the first cooperative multitasking or light-weight thread library. If you have used gevent or eventlet, you might find asyncio needs more explicit separation between synchronous and asynchronous code. This is usually a good thing.
Gevent, relies on monkey-patching to change blocking I/O calls to non-blocking ones. This can lead to hard to find performance issues due to an unpatched blocking call slowing the event loop. As the Zen says, ‘Explicit is better than Implicit’.
Another objective of asyncio was to provide a standardized concurrency framework for all implementations like gevent or Twisted. This not only reduces duplicated efforts by library authors but also ensures that code is portable for end users.
Personally, I think the asyncio module can be more streamlined. There are a lot of ideas which somewhat expose implementation details (e.g. native coroutines vs generator-based coroutines). But it is useful as a standard to write future-proof code.
Can we use asyncio in Django?
Strictly speaking, the answer is No. Django is a synchronous web framework. You might be able to run a seperate worker process, say in Celery, to run an embedded event loop. This can be used for I/O background tasks like web scraping.
However, Django Channels changes all that. Django might fit in the asynchronous world after all. But that’s the subject of another post.
This article contains an excerpt from "Django Design Patterns and Best Practices" by Arun Ravindran




