Do long term releases confuse you? For the longest time I was not sure which version of Ubuntu to download - the latest release or the LTS? I see a number of Django developers confused about Django’s releases. So I prepared this handy guide to help you choose (or confuse?).
Which Version To Use?
Django has now standardized on a release schedule with three kinds of releases:
Feature Release: These releases will have new features or improvements to existing features. It will happen every 8 months and will have 16 months of extended support from release. They have version numbers like A.B (note there’s no minor version).
Long-Term Support (LTS) Release: These are special kind of feature releases, which have a longer extended support of three years from the release date. These releases will happen every two years. They have version numbers like A.2 (since every third feature release will be a LTS). LTS releases have few months of overlap to aid in a smoother migration.
Patch Release: These releases are bug fixes or security patches. It is recommended to deploy them as soon as possible. Since they have minimal breaking changes, these upgrades should be painless to apply. They have version numbers like A.B.C
Django roadmap visualized below should make the release approach clearer:
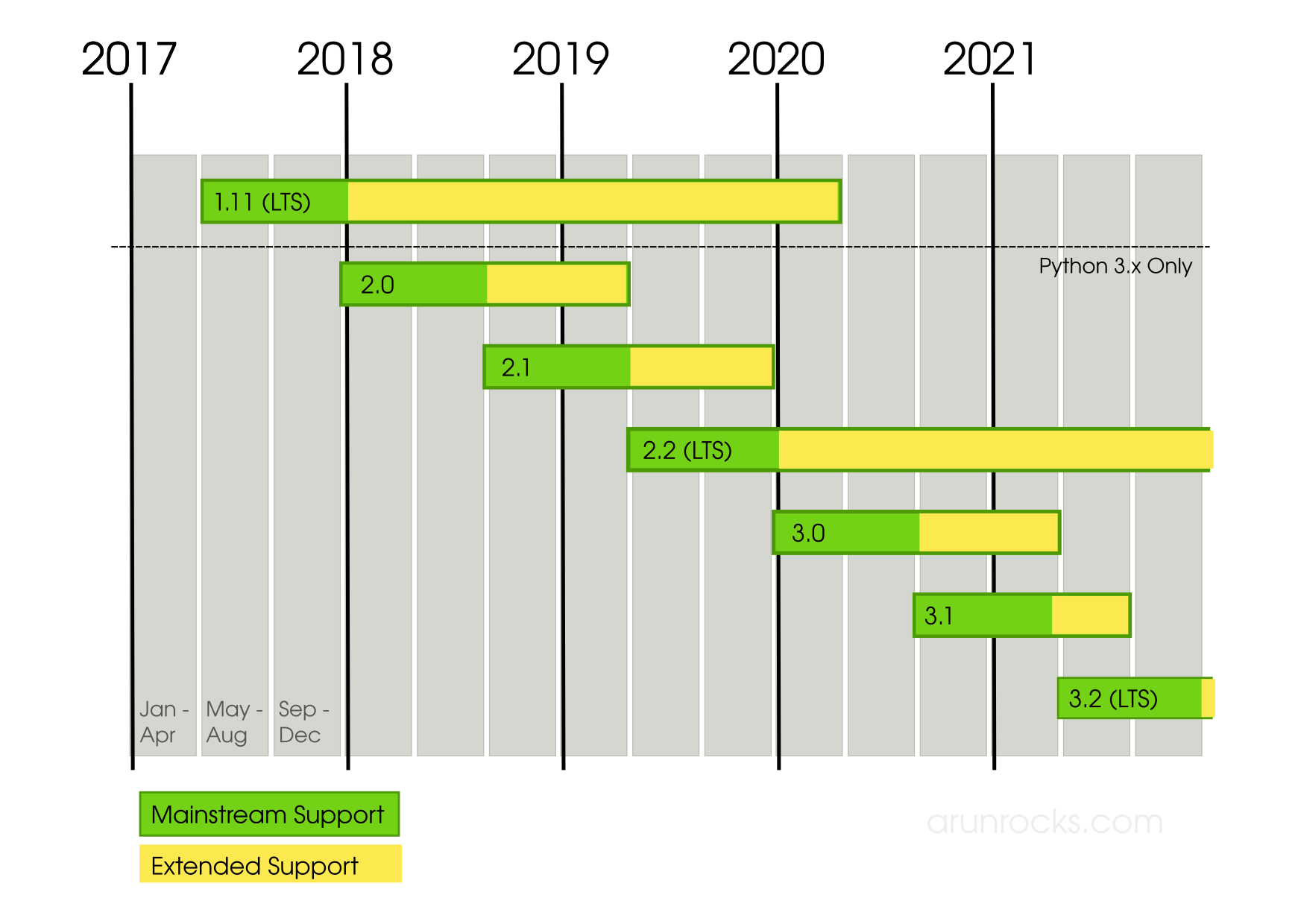
The dates are indicative and may change. This is not an official diagram but something that I created for my understanding.
The big takeaway is that Django 1.11 LTS will be the last release to support Python 2 and it is supported until April 2020. Subsequent versions will use only Python 3.
The right Django version for you will be based on how frequent you can upgrade your Django installation and what features you need. If your project is actively developed and the Django version can be upgraded at least once in 16 months, then you should install the latest feature release regardless of whether it is LTS or non-LTS.
Otherwise, if your project is only occasionally developed then you should pick the most recent LTS version. Upgrading your project’s Django dependency from one feature release to another can be a non-trivial effort. So, read the release notes and plan accordingly.
In any case, make sure you install Patch Releases as soon as they are released. Now, if you are still on Python 2 then read on.
Python 3 has crossed tipping point
When I decided to use Python 3 only while writing my book “Django Design Patterns and Best Practices” in 2015, it was a time when Python 2 versus Python 3 was hotly debated. However, to me Python 3 seemed much more cleaner without arcane syntax like class methods named __unicode__ and classes needing to derive from object parent class.
Now, it is quite a different picture. We just saw how Django no longer supports Python 2 except for the last LTS release. This is a big push for many Python shops to consider Python 3.
Many platforms have upgraded their default Python interpreter. Starting 1st March 2018, Python 3 is announced to be the default “python” in Homebrew installs. ArchLinux had completely switched to Python 3 since 2010.
Fedora has switched to Python 3 as its system default since version 23. Even though python command will launch python3, the symlink /usr/bin/python will still point to python2 for backward compatibility. So it is probably a good idea to use #!/usr/bin/env python idiom in your shell scripts.
On 26 April 2018, when Ubuntu 18.04 LTS (Bionic Beaver) will be released, it is planned to be have Python 3.6 as default. Further upstream, the next Debian release in testing - Debian 10 (Buster) is expected to transition to Python 3.6.
Moving to packages, the Python 3 Wall of Superpowers shows that with the backing of 190 out of 200 packages, at the time of writing, we have nearly all popular Python packages on Python 3. The only notable package remaining is supervisor, which is about to turn green in supervisor 4.0 (unreleased).
Common Python 3 Migration Blockers
You might be aware of atleast one project which is still on Python 2. It could be open source or an internal project, which may be stuck in Python 3 for a number of reasons. I’ve come across a number of such projects and here is my response to such reasons:
Reason 1: My Project is too complex
Some very large and complex projects like NumPy or Django have been migrated sucessfully. You can learn the migration strategies of projects like Django. Django maintained a common codebase for Python 2 and 3 using the six (2 × 3=6, get it?) library before switching to Python 3 only.
Reason 2: I still have time
It is closer than you think. Python clock shows there is a little more than 2 years and 2 months left for Python 2 support.
In fact, you have had a lot of time. It has been ten years since Python 3 was announced. That is a lot of overlap to transition from one version to another.
In today’s ‘move fast and break things’ world, a lot of projects decide to abruptly stop support and ask you to migrate as soon as a new release is out. This is a lot more realistic assumption for enterprises which need a lot more planning and testing.
Reason 3: I have to learn Python 3
But you already know most of it! You might need about 10 mins to learn the differences. In fact, I have written a post to guide Django coders to Python 3. Small Django/Python 2 projects need only trivial changes to work on Python 3.
You might see many old blog posts about Python 3 being buggy or slow. Well, that has not been true for a while. Not only it is extremely stable and bug-free, it is actually used in production by several companies. Performance-wise it has been getting faster in every release, so it is faster than Python 2 in most cases and slower in a few.
Of course, there are lot of awesome new features and libraries added to Python 3. You can learn them as and when you need them. I would recommend reading the release notes to understand them. I will mention my favourites soon.
Reason 4: Nobody is asking
Some people have the philosophy that if nobody is asking then nobody cares. Well, they do care if the application they run is on an unsupported technology. Better plan for the eventual transition than rush it on a higher budget.
Are you missing out?

To me, the biggest reason to switch was that all the newest and greatest features were coming to Python 3. My favourite top three exclusive features in Python 3 are:
-
asyncio: One of the coolest technologies I picked up recently. The learning process is sometimes mind-bending. But the performance boost in the right situations is incredible.
-
f-strings: They are so incredibly expressive that you would want to use them everywhere. Instant love!
-
dict: New compact dict implementation which uses less memory and are ordered!
Yes, FOMO is real.
Apart from my personal reasons, I would recommend everyone to migrate so that the community benefits from investing efforts into a common codebase. Plus we can all be consistent on which Python to recommend to beginners. Because…
There should be one– and preferably only one –obvious way to do it. Although that way may not be obvious at first unless you’re Dutch.
This article contains an excerpt from the upcoming second edition of book "Django Design Patterns and Best Practices" by Arun Ravindran