Daniel Roy Greenfeld needs no introduction to Djangonauts. Co-author of the book Two Scoops of Django which is probably on the shelves of any serious Django practitioner. But PyDanny, as he is fondly known as, is also a wonderful fiction author, fitness enthusiast and a lot more.
Having known Daniel for a while as a wonderful friend and a great inspiration, I am so excited that he agreed to my interview. Let’s get started…

How did the idea of writing an ice-cream themed book occur?
The first 50 pages that I wrote were angry and were for a book with an angry name. You see, I was tired of having to pick up after sloppy or unwise coding practices on rescue projects. I was furious and wanted to fix the world.
However, I was getting stuck in what I wanted to say, or didn’t know things. I kept asking my normal favorite resource for help, Audrey Roy Greenfeld. Eventually she started to write (or rewrite) whole sections and I realized that I wasn’t writing the book alone.
Therefore I asked Audrey to be my co-author. She’s a cheerful person and said that if she were to accept, the book had to be lightened. That meant changing the name. After a lot of different title names discussed over many ice cream sessions, we decided to use the subject matter at hand. Which worked out well as the ice cream theme made for a good example subject.
How do you and Audrey collaborate while writing a book?
We take turns writing original material that interests us. The other person follows them and acts as editor and proofreader. We go back and forth a few hundred times and there you go.
For tech writing we use Git as version control and LaTeX for formatting. For fiction we use Google docs followed by some Python scripts that merge and format the files.
What’s the most exciting recent development in Django? Where do you think it can improve?
I like the new URL system as it’s really nice for beginners and advanced coders alike. While I like writing regular expressions, I’m the exception in this case.
Where I think where Django can improve is having more non-US/Europe/Australian representation within the DSF and in the core membership. In short, most of Django core looks like me, and I think that’s wrong. Many of the best Django (and Python) people look nothing like me, and they deserve more recognition. While having Anna Makarudze on the DSF board is a wonderful development, as a community we can still do better in core.
In the case of Django’s core team, I believe this has happened because all the major Django conferences are in the US, Europe, and Australia, and from what I’ve seen over the years it’s through participation in those events is how most people get onto the Django core team. The DSF is aware of the problem, but I think more people should raise it as an issue. More people vocalizing this as a problem will get it resolved more quickly.
With the Ambria fantasy series, you have proven to be a prolific fiction author too. Reminds me Lewis Carroll who wrote children’s books and mathematical treatises. What is the difference in the writing process while writing fiction and non-fiction?
For us, the process is very similar. We both write and we both review our stuff. The difference is that if we make a mistake in our fiction, it’s not as critical. That means that the review process for fiction is a lot easier on us then it is to write technical books or articles. I can’t begin to tell you what a load that is off my shoulders.
Why fantasy? Any literary influences?
We like fantasy because we can just let our imaginations run away with us. For the Ambria series, our influences include Tolkien, Joseph Campbell, Glen Cook, Greek mythology, and various equine and religious studies.
Do you have a daily writing routine?
Like coding on a fun project, when we get to write, we get up early and just start working. When we get hungry or thirsty we stop. The day seems to fly by and we are very happy. We try not to mix writing days with coding days, as we like to focus on one thing at a time. Neither of us are big believers in multi-tasking, so sticking to one thing is important to us.
What’s your favorite part of the writing process?
Getting to write with my favorite person in the whole world, Audrey Roy Greenfeld. :-)
Also, having people read our stuff and comment on it, both positively and negatively.
Do you ever get writer’s block?
Not usually. Our delays are almost always because of other things getting in the way. We’re very fortunate that way!
When I do get writers block, I try to do something active. Be it exercise or fix something in the house that needs it.
Considering you can do cartwheels, I am assuming you are pretty fit. Do you think technology folks don’t give it enough importance?
I’m older than I look but even dealing with an unpleasant knee injury move faster and better than 90% of software developers. And when I look at other coders my age, I see people old before their years. I believe youth is fleeting unless you take a little bit of time every day to keep your strength and flexibility.
Anything else you would like to say?
To paraphrase Jurassic Park, “Just because you can do a thing doesn’t mean you should do a thing.”
As software developers, we have skills that let us do amazing things. With enough time and experience, we can do pretty much anything we are asked to do. That said, we should consider whether or not we should always do what we are asked to do.
For example, the combined power of image recognition, big data, and distributed systems is really fun to play with, but we need to be aware that these tools can be dangerous. In the past year we’ve seen it used to affect opinion and elections, and this is only the beginning. It’s our responsibility to the future to be aware that the tools we are playing with have a lot of power, and that the people who are paying us to use them might not have the best intentions.
Hence why I like to say, “Just because you can do a thing doesn’t mean you should do a thing.”
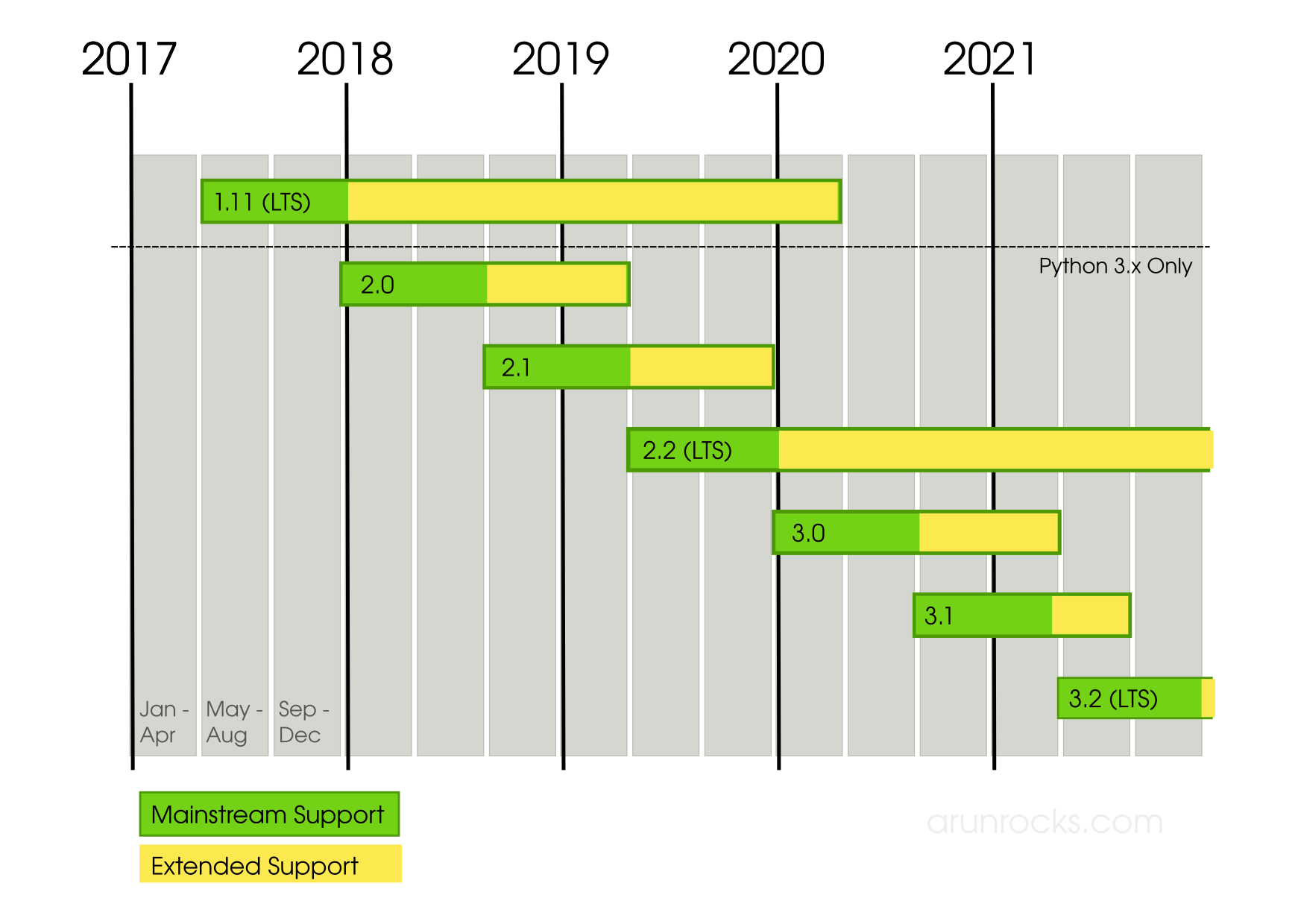
Do checkout “Two Scoops of Django 1.11: Best Practices for the Django Web Framework” by Two Scoops Press











![my first lesson on friendship!! [Explored 08-11-2011 #75]](https://farm7.staticflickr.com/6092/6325453201_eb743b8977.jpg)

